
I recently decided to branch out from my typical AWS realm and try out Microsoft Azure’s CosmosDB. Here’s a quick look at how the process went along with my off-the-cuff thoughts about the service.
After logging in to the Azure Portal I went to the Azure Cosmos DB section and clicked “Add”. This is where things got a little weird. Coming from the AWS-world where I usually create all my cloud resources within one “account” Azure doesn’t conceptually meld with the world I’m used to. It initially prompts you to “Create Azure Cosmos DB Account”:
The vernacular of “account” here seems common across Azure, but it’s a bit confusing. I already have a “Microsoft Account” I used to sign in. Why do I need another “account”? But okay fine, I’ll give you this one Azure and just map “account” in my head to “thing that contains a single cloud resource”. Except wait, I can’t do that because you also have “Storage accounts” which contain blog storage, queues, tables, and a bunch of other resources all in the same “account”. Why does this have to be so confusing? Great question.
Anyway, to begin with CosmosDB, I select one of my “Subscriptions” (and don’t get me started on how the term ‘subscription’ should just be some syllable for ‘container’ as we’re not actually paying regularly for anything unless we create something inside of it).
After I do this, I also put the database in a resource group, and give the CosmosDB account a name. The next part is to pick an API to use with CosmosDB
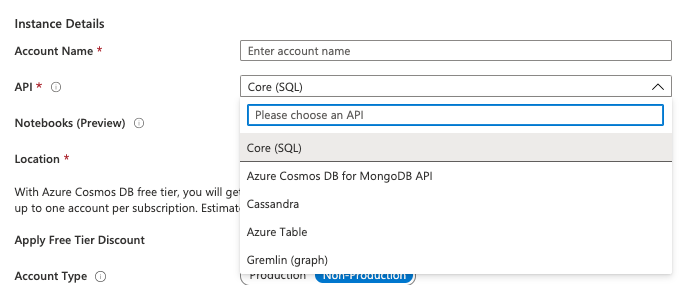
This brings up an interesting and somewhat confusing part of CosmosDB. What is it? Is it a document database with SQL-style queries supported? A graph database? A MongoDB clone? Apparently it is all of these and more. But why isn’t it more than one service?
If I have to select a specific API can I change it later? Does it have performance implications? The answers to these questions were not clear when creating the database. I found out later, that I cannot change the API I use without migrating it to a new databases. So really, there is a GraphmosDB, a MongomosDB, and a few others that are interacted with in different ways. I can’t imagine how fun keeping the documentation clean is there.
After selecting “Core SQL” and moving through the other steps with the default options the next steps are to select Networking, Encryption and Tags. Easy enough, now I should be able to press create and start working with this thing once it’s created in a few seconds right? The “estimated creation time” of 15 minutes can’t be real right?
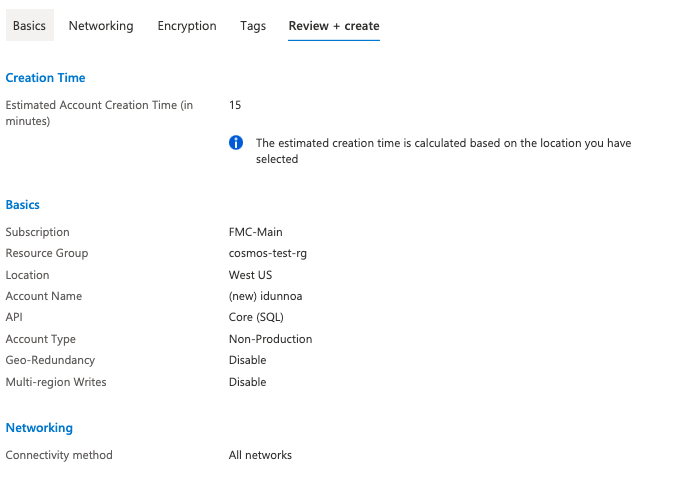
15 minutes later
Apparently it can. Wow. You really can’t pre-provision something there so I can start faster? I guess I am unfairly comparing this to a DynamoDB table which spins up in under a minute. I imagine a comparably-sized Amazon RDS instance might take as long. But that’s a speed test for another day.
So now that my deployment has finished I’m ready to start actually playing with the tool. I click in to the “data explorer” section and click “DB” then “Items”. At this point, the items now make up approximately 5% of the screen and are barely visible. Interesting UI defaults, but okay fine.
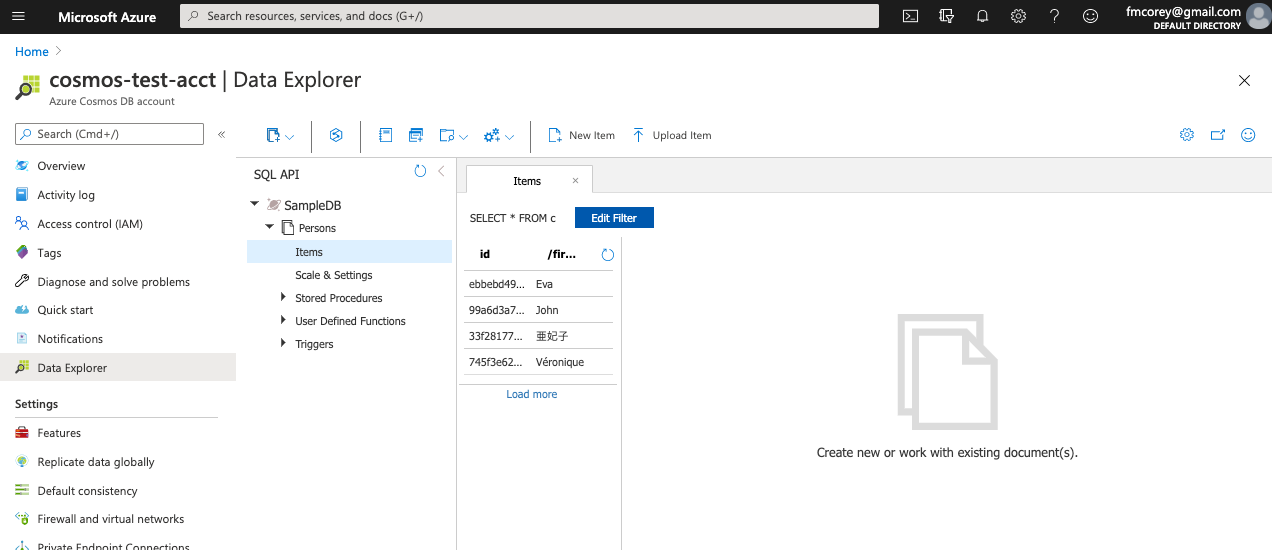
Now that I can see the sample “Persons” data pre-loaded in for me I think “cool, now what?”. How do I query?
This silly uneducated question could have been easily solved if I’d realized that one of the most common things I’d want to do when working with a database would of course be represented by literally less than 1% of the screen’s real estate. I’ll give you a hint, writing a query is possible after clicking one of these icons:
![]()
Can you guess which one? I’ll give you a hint, it’s not the icon with the magnifying glass which only a plebeian like myself would have initially guessed it might be. It’s actually the one with the plus icon. No not that one, the other one. It’s okay, you’ll figure it out and definitely not confuse the two over and over again when learning the tool like I did.
Anyway, now that I know how to write a query using this new query window we can do the fun stuff.
Thanks to the example, I already have some data in the database and it populates a default SELECT * FROM c query in there for me. In this case c is apparently the container that we’re interacting with. We just need to name that and then query the properties we want right?
So let’s get the firstname of all these people:
SELECT firstname FROM c
Oops:
Failed to query item for container Persons: {“code”:400,“body”:{“code”:“BadRequest”,“message”:“Gateway Failed to Retrieve Query Plan: Message: {"errors":[{"severity":"Error","location":{"start":7,"end":16},"code":"SC2001","message":"Identifier ‘firstname’ could not be resolved."}]}\r\nActivityId: 9f13938c-c1bb-40ff-98e0-0d4b9d869de1, Microsoft.Azure.Documents.Common/2.11.0, Microsoft.Azure.Documents.Common/2.11.0”},“headers”:{“access-control-allow-credentials”:“true”,“access-control-allow-origin”:“https://cosmos.azure.com”,“content-type”:“application/json”,“strict-transport-security”:“max-age=31536000”,“x-ms-activity-id”:“9f13938c-c1bb-40ff-98e0-0d4b9d869de1”,“x-ms-gatewayversion”:“version=2.11.0”,“x-ms-throttle-retry-count”:0,“x-ms-throttle-retry-wait-time-ms”:0},“activityId”:“9f13938c-c1bb-40ff-98e0-0d4b9d869de1”}
Contained within this wonderfully dense error is the information that our Identifier 'firstname' could not be resolved.
Turns out, this is because this is “SQL” in the same way that Good & Plenty is “candy”. When using CosmosDB’s Core SQL API we need to select items from the documents using the “container” as the top level thing and anything under it represented with a dot syntax. For example, if we want to get the firstname we need to do:
SELECT c.firstname FROM c
This will get us back:
[
{
"firstname": "Eva"
},
{
"firstname": "John"
},
{
"firstname": "亜妃子"
},
{
"firstname": "Véronique"
}
]
But this is a bit verbose, in my response I probably don’t want every firstname in a separate object. To make this a more concise response we can use SELECT VALUE:
SELECT VALUE c.firstname FROM c
[
"Eva",
"John",
"亜妃子",
"Véronique"
]
This all seems straightforward enough, and despite my complaints a fun service to work with. Coming from using DynamoDB more exclusively I have some general questions about optimization and scale that I’m concerned might emerge eventually when I realize I’ve probably created a new CosmosDB database with an improperly selected partition key. But nothing significantly more than any other relational or document database. I’m looking forward to playing with CosmosDB and it’s other APIs later on as I work more with Microsoft Azure.