
Recently, I needed to put together system that would take new DynamoDB table items, queue up JSON messages in first-in-first-out order, and trickle them out to a 3rd party API over time.
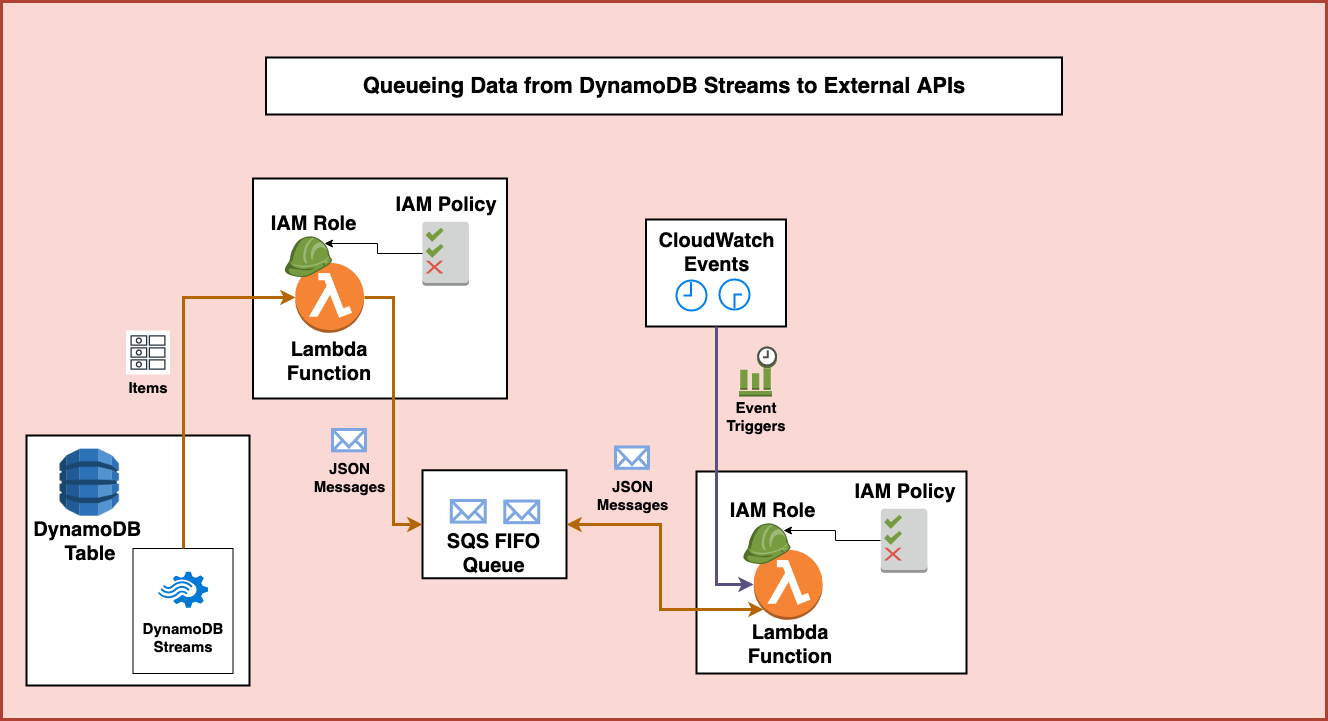
I love not having to maintain things later so I decided to throw together a solution on top of managed AWS services. Here’s a high-level diagram of what I came up with:
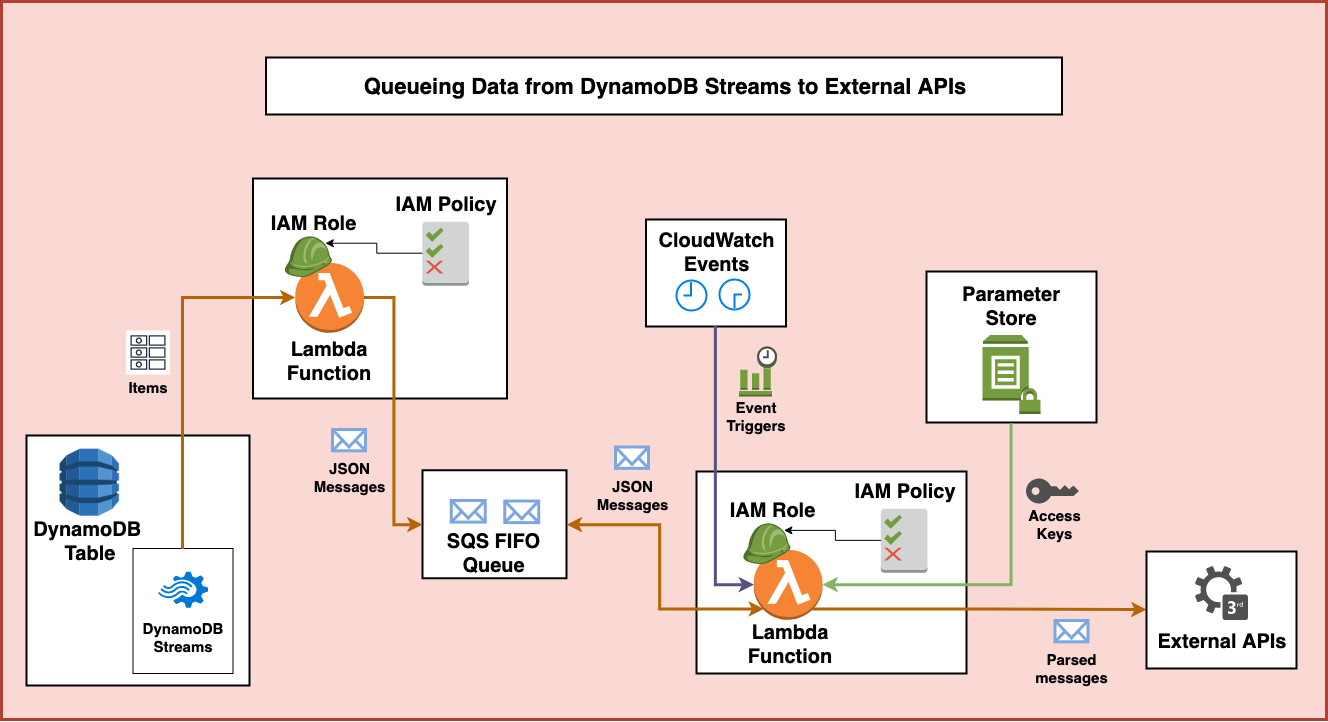
Let’s take a look at how it all works.
First, items are added to a DynamoDB table that gets written to and read from multiple different sources. In order to avoid using additional ready and write capacity on the table, we can use DynamoDB Streams to take action on any changes to the table. DynamoDB Streams will provide us with a real-time stream of all new, deleted, or updated items on the table.

Using DynamoDB Streams, we can set up an integration with AWS Lambda to look for and process newly added items. This will allow us to process all the table changes and see whenever new records are added. This requires us to create a Lambda function with the necessary permissions from an IAM role and policy to access DynamoDB streams.

The Lambda function will then be used to isolate newly inserted items and parse the data for only those new items. In this process it will create a JSON message payload to send to a existing Amazon Simple Queue Service (SQS) First-in-first-out (or FIFO) queue. The permissions associated with the Lambda function must also allow it to send messages to SQS.
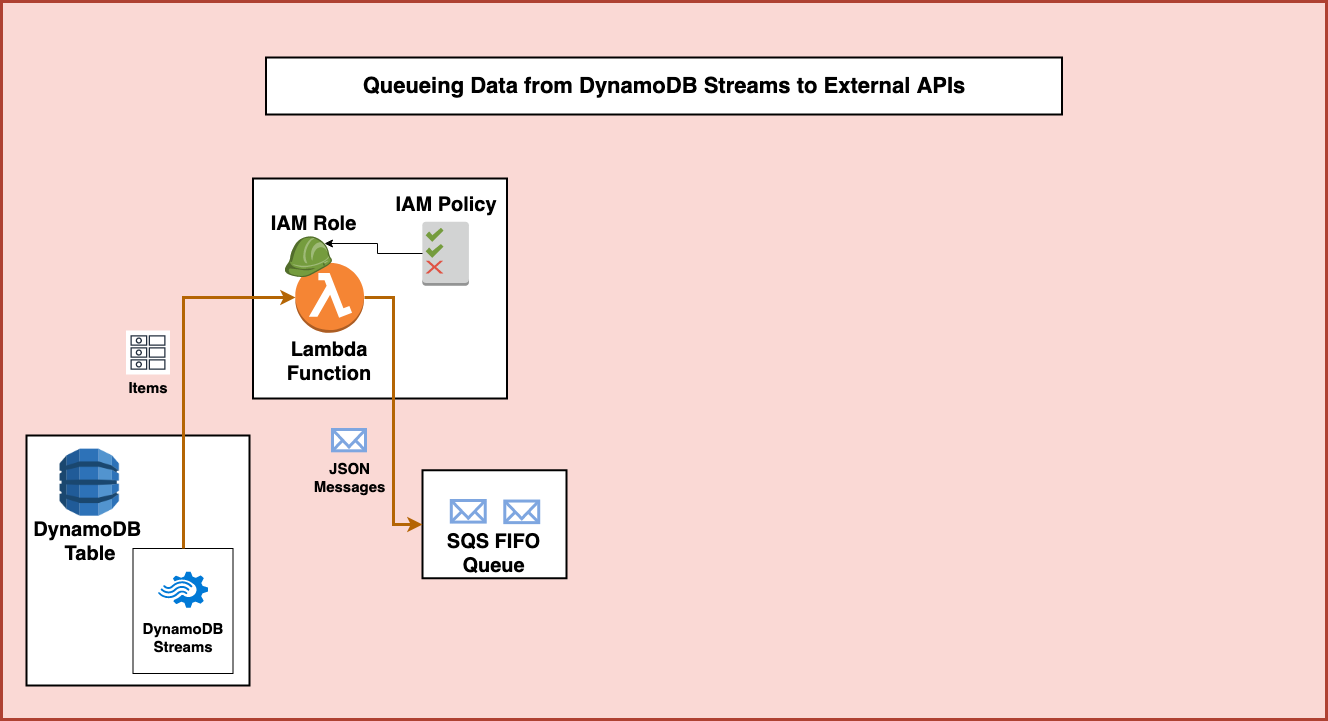
This queue stores the messages in the order they are received and guarantees that they are retried and processed in the same first-in-first-out order. When appropriate, this first portion of the architecture could be separated and the next portion could be replaced by any other consumer depending on the nature of the work to be performed.
In this case, the second half of the architecture starts with Amazon CloudWatch Events. These events are setup to trigger at various times using either a rate or cron trigger. The rate trigger can run every few minutes, hours, or days. Whereas the cron trigger allows scheduling events at a particular time. In this case, we set up several cron triggers to schedule the processing of the SQS data at particular times.
These CloudWatch Event Triggers are integrated with a second AWS Lambda function. This function also has a role and policy associated with it in order to provide it permissions to access the required services.
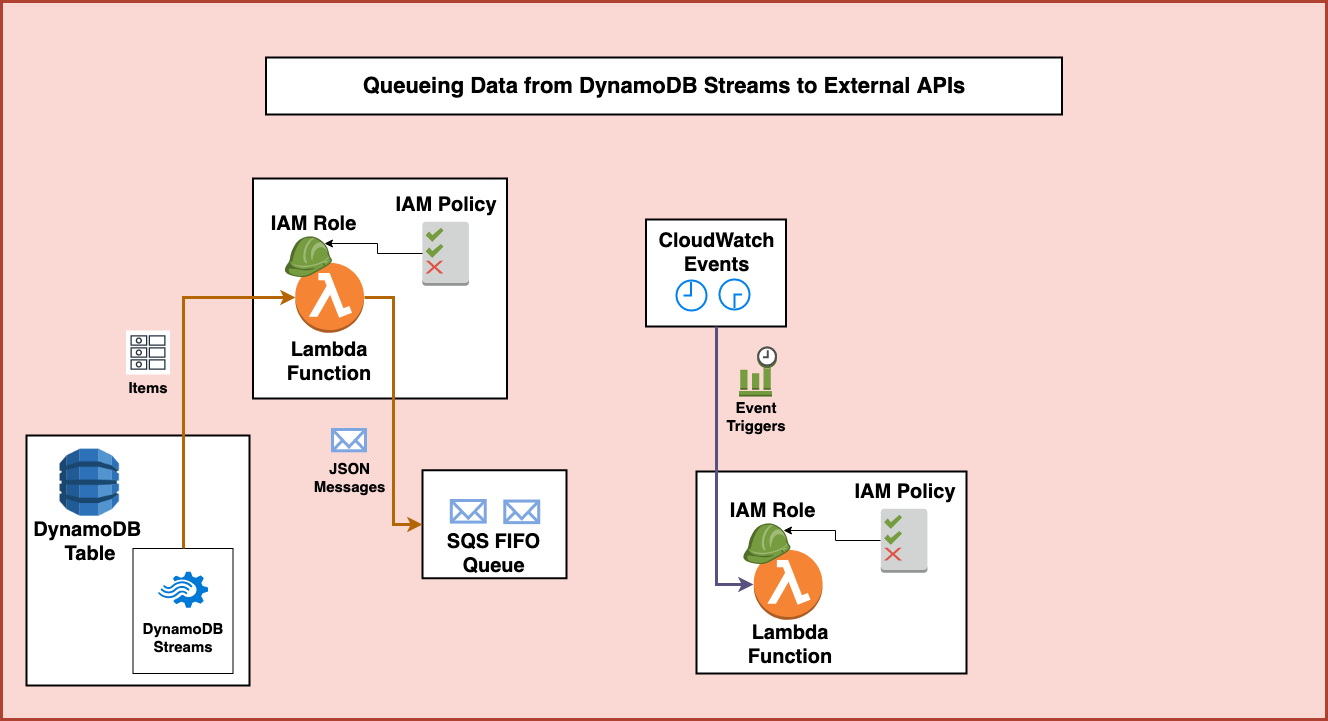
It starts by accessing the SQS queue and retrieving the oldest message for processing. Because this is a First-in-first-out queue it is guaranteed to be the message that was first put into the queue and hasn’t been deleted yet.
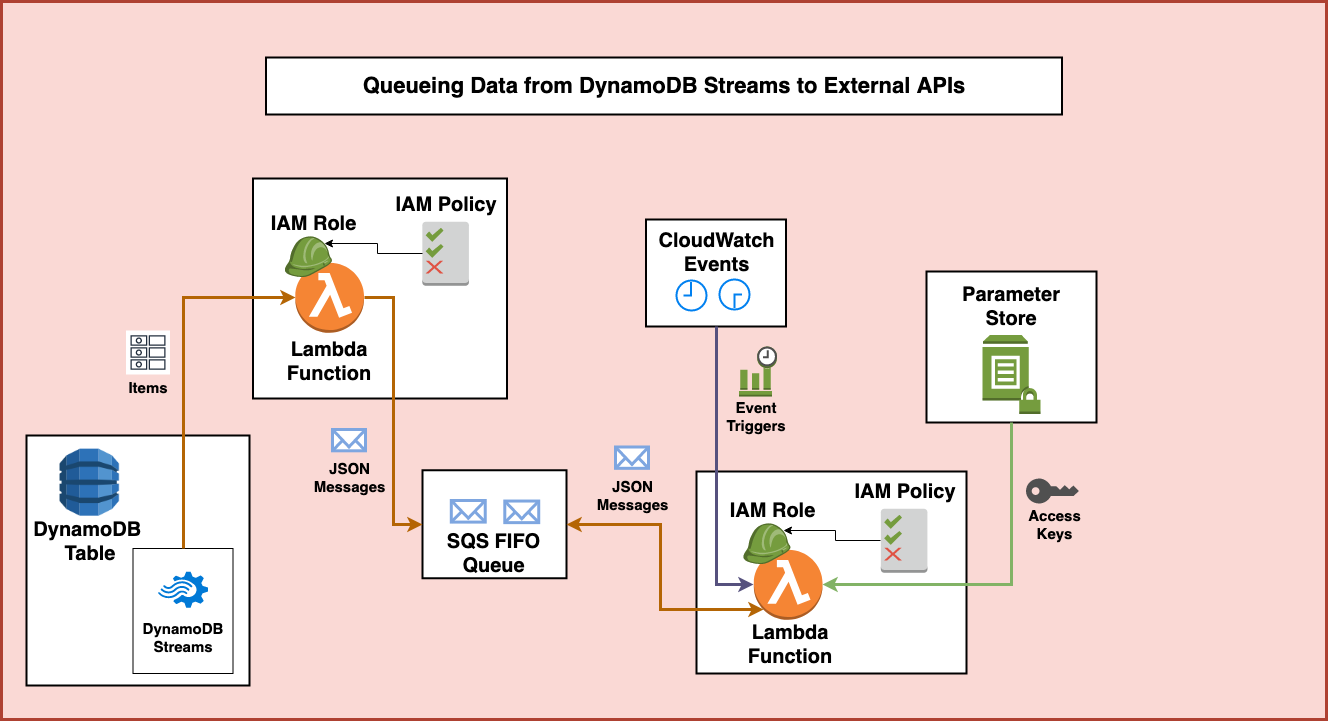
After the SQS message is retrieved, the Lambda Function also makes a call to the AWS Parameter Store to retrieve access keys. The permissions the Lambda function has allow it to get these keys from the service and avoid having to store any keys in source control. Instead, the keys are stored and encrypted securely in Parameter Store.
The Lambda function then uses the access keys to create clients to interact with the external services. Then, the Lambda function prepares the data from SQS and sends requests to the external APIs. Then the data from SQS is structured appropriately and sent over to the APIs.
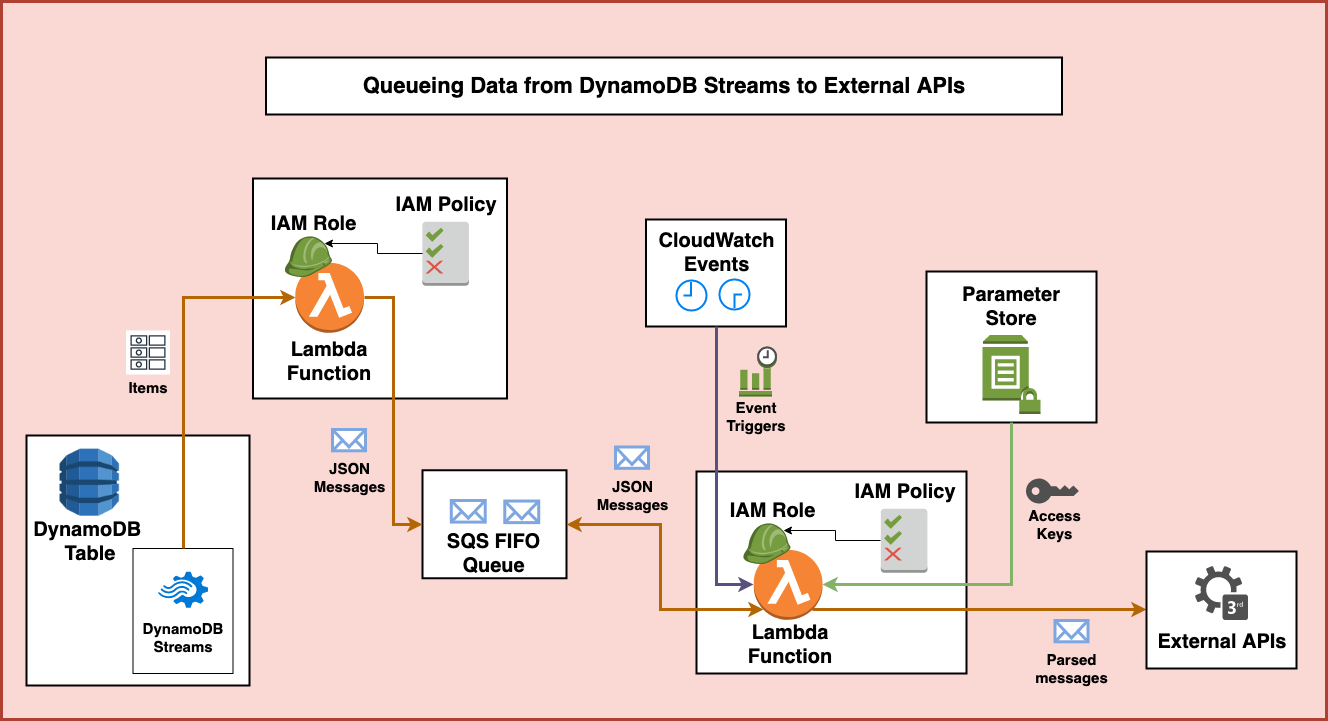
After the Lambda function sees a successful 200 response from the APIs it can safely go back to the SQS and delete the processed message.
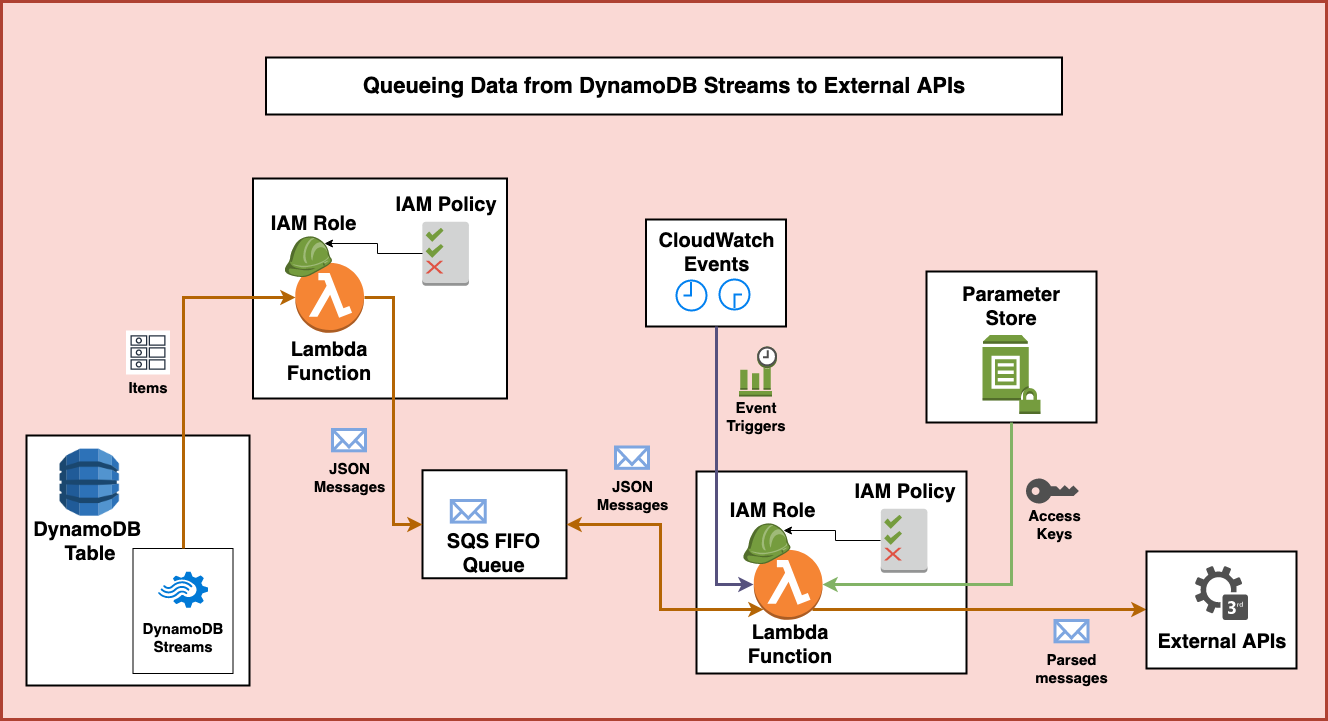
With all of this completed, the second Lambda function stops running until another CloudWatch Event trigger spins it up again at a later time. This system by itself should run independently on it’s own without having to manage any server infrastructure. It also allows the rate of incoming data to fluctuate regularly and not impact the way the data is processed in the long run.
Does this sort of architecture sound like something you’d like to see implemented in your organization? Leave a comment below or get in touch!